Picture this
You release an update. Nothing crashes. No one scrambles. No one gets paged. That calm isn’t luck. It’s design. It comes from watching your software before it goes live, not after.
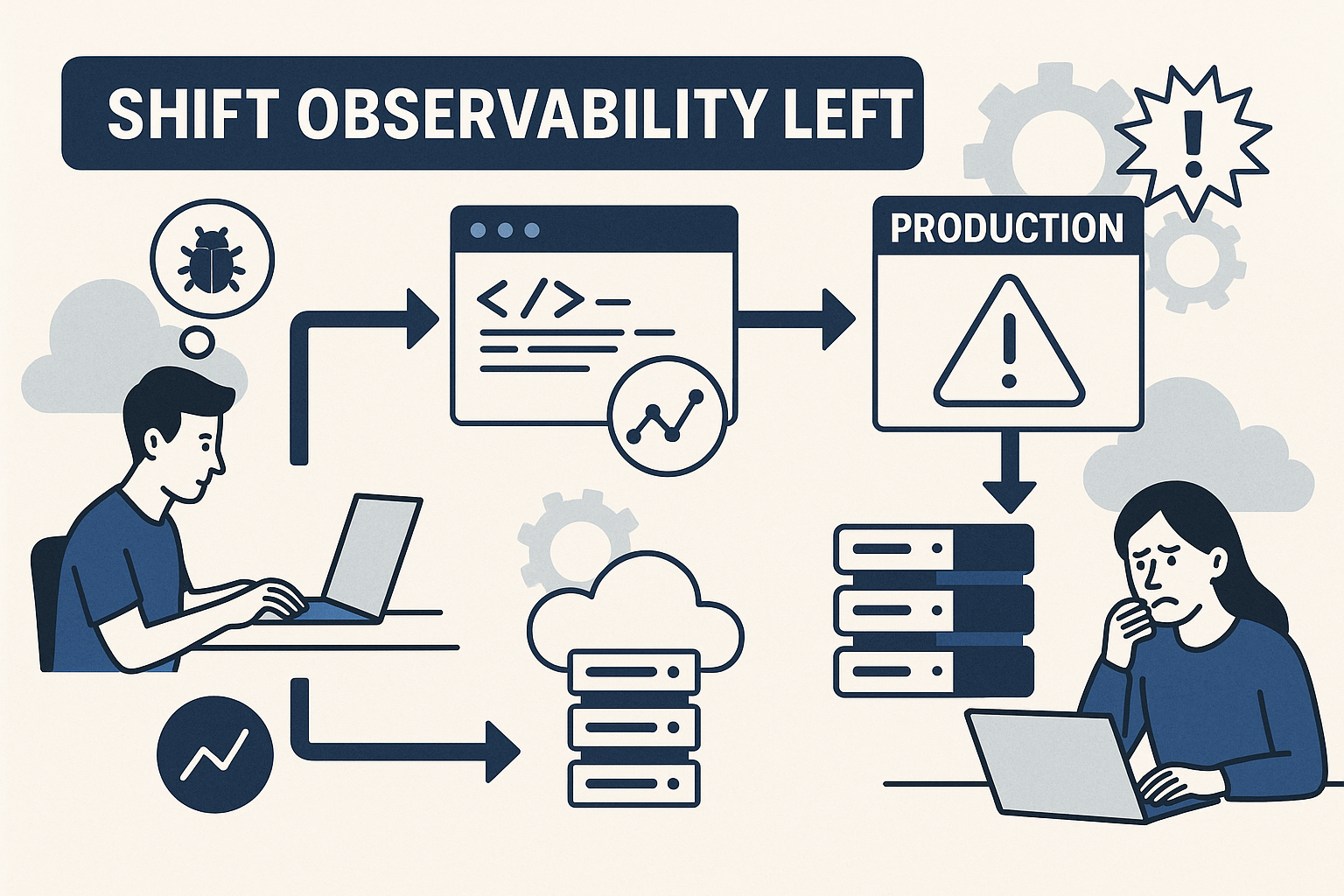
That’s what shifting observability left means in CI/CD. Move feedback from the end of the pipeline to the beginning, and the whole process changes. You catch problems while they’re still cheap. You spend less time guessing. And when something breaks, it breaks small.
What Observability Looks Like in CI/CD
CI/CD helps ship faster. But most teams still rely on tools that speak up after the fact, after the code is deployed and users run into trouble.
The alternative: monitor early. Watch how things behave during the build, not after the release. That’s Shift Observability Left.
You don’t have to watch everything. But you do have to listen sooner.
Why It Works
This switch pays off in four clear ways:
- You catch issues fast—before they hit users.
- You cut down on outages.
- You trust your releases more.
- Your developers spend less time in firefights and more time building.
Think of a bug in vehicle software. If it’s spotted during build time, it might take minutes to fix. If it shows up on the road, it costs weeks and millions.
How CI/CD Looks After the Shift
Here’s what changes when observability starts early:
- Metrics show up inside the integration stage. Not after.
- Regression tests run with every build, not every Friday.
- Debugging times drop because problems appear sooner.
- Systems use fewer resources, not more, to do the same work.
Audi’s Results with LOCI
Audi’s ADAS team had a problem. Long testing cycles. Limited access to source code. Gaps in collaboration with suppliers.
So they used LOCI.
Instead of waiting on logs or code reviews, LOCI read their compiled binaries. It flagged issues buried deep in the build. What changed?
- Test time dropped from 6 days to 3.4.
- Subtle problems were found before launch.
- Supplier issues got resolved faster.
And this wasn’t isolated. VW Group applied LOCI across multiple workflows, improving diagnostics and debugging across the board.
How to Make the Shift Happen
Start with a plan you can grow from:
- Pick tools that don’t slow you down. If setup takes a week, skip it. You need speed and prediction.
- Insert observability early. Not just pre-production—pre-merge, pre-build.
- Define baselines. Track what matters: latency, throughput, energy, memory. Then trigger alerts when things shift.
- Automate your response. Don’t just notify. Act. Let AI trigger fixes or rollbacks when thresholds break.
Tools like LOCI work well here because they handle compiled code directly. That means fewer blind spots and fewer assumptions.
Where LOCI Fits In
LOCI looks where other tools can’t. It watches the compiled binary, not just the code that wrote it.
That’s where you find the edge cases—the memory leaks, the GPU overuse, the performance drag.
It uses a Large Code Language Model (LCLM) trained to spot what normal tools miss. That’s how Audi dropped their failure rate and saved days of testing time.
Don’t Get Stuck Here
Two things can ruin early observability:
- Overdoing it. You don’t need to track everything. Track what slows you down.
- Resistance. Teams are used to fixing after the fact. Shifting that mindset takes time.
Start small. Automate where you can. Teach with examples. And measure what improves.
Where This Goes Next
Software is getting harder. Deadlines are getting tighter. Bugs are still bugs.
What changes is how early we see them. That’s where machine learning comes in. Soon, pipelines won’t just build and test. They’ll guess what might break and stop it before it starts.
Teams that get there first? They’ll ship faster, with fewer bugs, and less drama.
Final Word
Early observability isn’t a luxury. It’s a shield.
You want faster cycles? Fewer bugs? Lower costs? This is the switch to make.
Don’t wait for something to break to figure out how it broke. Shift the feedback left. It works.